下面我将从“是什么”、“为什么”、“怎么做”以及“风险与挑战”四个方面,系统地阐述政府决策与互联网数据的关系。
(图片来源网络,侵删)
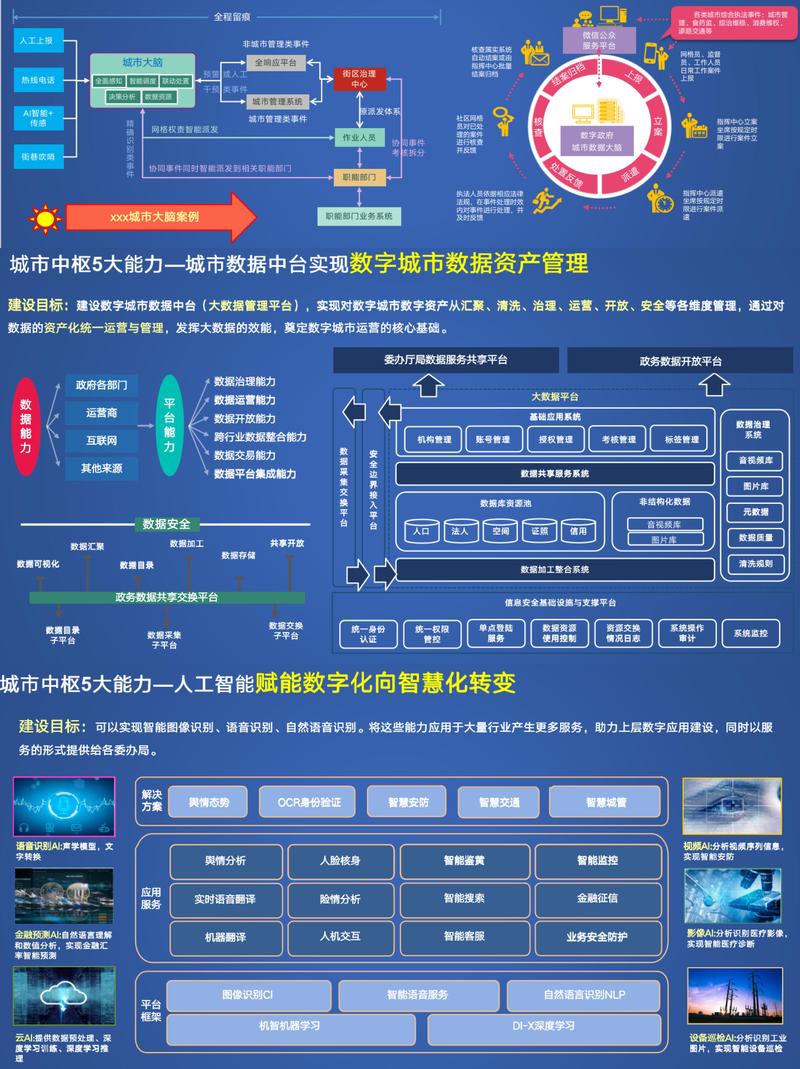
是什么:互联网数据如何赋能政府决策?
互联网数据是指通过互联网产生、收集和存储的海量信息,它构成了现代社会运行的“数字脉搏”,政府决策利用这些数据,本质上是从传统的“经验驱动”和“抽样调查”转向“数据驱动”和“全景洞察”。
主要的数据类型包括:
- 社交媒体数据: 微博、微信、抖音、Twitter、Facebook等平台上的用户评论、转发、点赞、话题讨论,它能实时反映公众情绪、热点事件和舆情走向。
- 搜索引擎数据: 百度、谷歌等用户的搜索关键词,它能揭示公众的关注点、信息需求和潜在的社会需求。
- 电子商务数据: 淘宝、京东、拼多多等平台的商品交易、用户评价、物流信息,它能反映消费趋势、区域经济活力和民生需求。
- 移动信令/位置数据: 运营商记录的匿名手机位置信息,它能用于分析城市人口流动、职住关系、交通拥堵热点等。
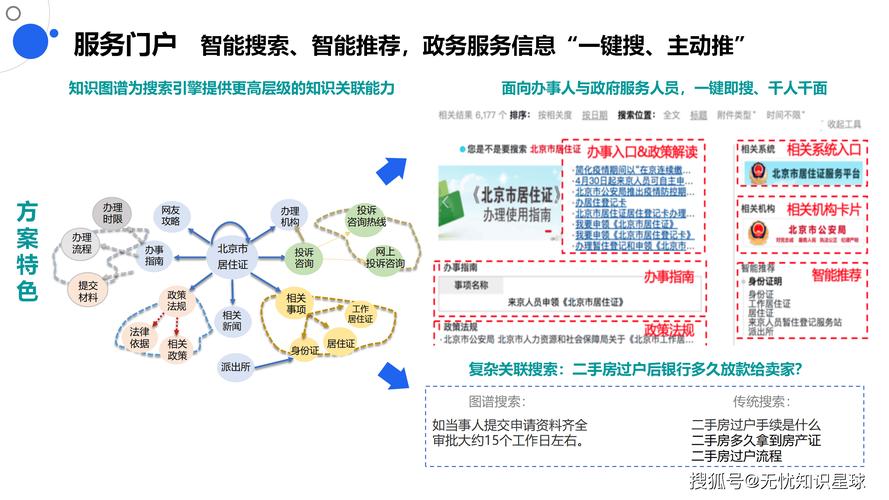
- 政府服务与互动数据: 政府网站、App(如“浙里办”、“随申办”)的访问量、办事流程、用户反馈等,它能评估政府服务的效率和公众满意度。
- 物联网数据: 智能交通摄像头、环境监测传感器、智能水表电表等设备收集的数据,它能用于智慧城市精细化管理。
为什么:互联网数据对政府决策的价值
利用互联网数据进行决策,可以显著提升政府的治理能力。
-
提升决策的科学性与精准性
 (图片来源网络,侵删)
(图片来源网络,侵删)- 告别拍脑袋: 传统决策可能依赖有限的经验或报告,互联网数据提供了海量的、多维度的客观依据,使决策有据可依。
- 精准画像: 通过数据分析,政府可以构建更精准的公众画像、企业画像和城市画像,分析消费数据可以更精准地发放消费券,分析就业数据可以更有针对性地开展职业培训。
-
增强决策的预见性与前瞻性
- 预测趋势: 通过对搜索指数、社交媒体讨论趋势的分析,可以提前预判某些社会问题(如特定疾病的关注度、某种社会矛盾的发酵)或经济趋势(如新的消费热点)。
- 预警风险: 实时监测舆情数据,可以在公共事件爆发初期发现苗头,及时介入,防止事态扩大,通过监测“XX小区停电”等关键词的集中爆发,市政部门可以快速响应。
-
优化公共服务的供给效率
- 需求驱动: 了解民众在互联网上反映的“急难愁盼”问题,可以更有针对性地设计和推出公共服务,根据家长在育儿论坛的讨论,增加普惠性托育服务。
- 流程再造: 分析政务服务App的用户行为数据,发现办事流程中的堵点和难点,从而简化流程、减少证明材料,实现“一网通办”的优化。
-
创新社会治理模式
- 精细化城市治理: 利用交通、环境、人流等数据,实现交通信号灯的智能配时、垃圾分类的精准投放、公共设施的动态维护。
- 应急响应: 在自然灾害(如台风、洪水)期间,通过位置数据预测受影响人群,进行精准疏散和救援资源调配。
怎么做:应用场景与实践案例
互联网数据在政府决策中的应用已经渗透到多个领域。
(图片来源网络,侵删)
| 应用领域 | 具体场景 | 数据来源 | 案例/效果 |
|---|---|---|---|
| 宏观经济 | 监测经济活力、预测消费趋势 | 电商交易数据、支付数据、招聘网站数据 | 国家统计局等机构会参考电商平台数据来评估社会消费品零售总额等指标的准确性。 |
| 市场监管 | 打击假冒伪劣、维护市场秩序 | 电商评论数据、社交平台投诉数据、企业信用数据 | 市场监管部门可以分析大量差评,快速锁定问题产品和商家,进行定向抽检和查处。 |
| 公共安全 | 预警社会风险、打击犯罪 | 舆情监测数据、社交媒体数据、警务数据 | 公安部门通过分析网络谣言的传播路径,快速辟谣,防止恐慌蔓延。 |
| 城市管理 | 智慧交通、智慧环保 | 移动信令数据、交通摄像头数据、环境传感器数据 | 杭州等城市的“城市大脑”通过分析实时路况数据,智能调控红绿灯,缓解交通拥堵。 |
| 卫生健康 | 疫情监测、公共卫生预警 | 搜索指数(如“咳嗽”)、社交媒体讨论、医院挂号数据 | 在新冠疫情期间,多地通过监测“发热”、“咳嗽”等关键词的搜索量上升,来辅助预警。 |
| 应急管理 | 灾害预警与救援 | 气象数据、社交媒体求助信息、位置数据 | 在地震或洪水后,通过分析用户发布的带有地理位置标签的求助信息,可以快速定位受困人员。 |
风险与挑战:一把双刃剑
尽管价值巨大,但滥用或误用互联网数据会带来严重风险。
-
隐私泄露与数据安全风险
- 核心问题: 互联网数据中包含大量个人隐私信息,政府在收集、存储和使用过程中,如果保护措施不当,极易发生数据泄露,侵犯公民的隐私权和人身安全。
- 挑战: 如何在数据利用与隐私保护之间找到平衡点?如何建立严格的数据脱敏、访问控制和审计机制?
-
数据偏见与算法歧视
- 核心问题: 互联网数据本身可能存在“偏见”,上网的群体不能完全代表全体国民(如老年人、低收入群体可能上网较少),如果基于这种有偏见的数据进行决策,可能会加剧社会不公。
- 挑战: 如何确保数据的代表性和全面性?如何审查算法模型,避免其放大或固现存的歧视(如在信贷、招聘等领域)?
-
数据质量与“数字鸿沟”
- 核心问题: 互联网数据鱼龙混杂,存在大量虚假信息、垃圾数据,如何清洗和甄别有效数据是一大难题,不同地区、不同人群在数字接入和使用能力上存在差距,可能导致“数字鸿沟”,使一部分人的声音被数据所忽略。
- 挑战: 建立数据质量评估体系,并结合传统调研方法(如入户访谈、电话问卷)来弥补互联网数据的盲区。
-
“数字利维坦”与权力滥用
- 核心问题: 政府掌握海量数据后,可能形成前所未有的监控能力,如果缺乏有效的法律和制度约束,这种权力容易被滥用,用于压制异见、进行社会控制,损害公民自由。
- 挑战: 如何建立健全的数据治理法律法规?如何确保数据采集和使用的透明度与问责制?如何划定政府权力的边界?
-
决策过程的“黑箱化”与公众信任危机
- 核心问题: 当政府越来越多地依赖复杂的算法和数据进行决策时,决策过程可能变得不透明,公众不理解“为什么”要这样做,容易产生不信任感和抵触情绪。
- 挑战: 如何提高算法决策的可解释性?如何建立公众参与和监督机制,确保数据决策的民主化和正当性?
互联网数据是政府治理现代化的强大引擎,它能够让政府更“聪明”、更“高效”、更“懂民意”,这把剑的剑柄必须握在法治、伦理和责任的手中。
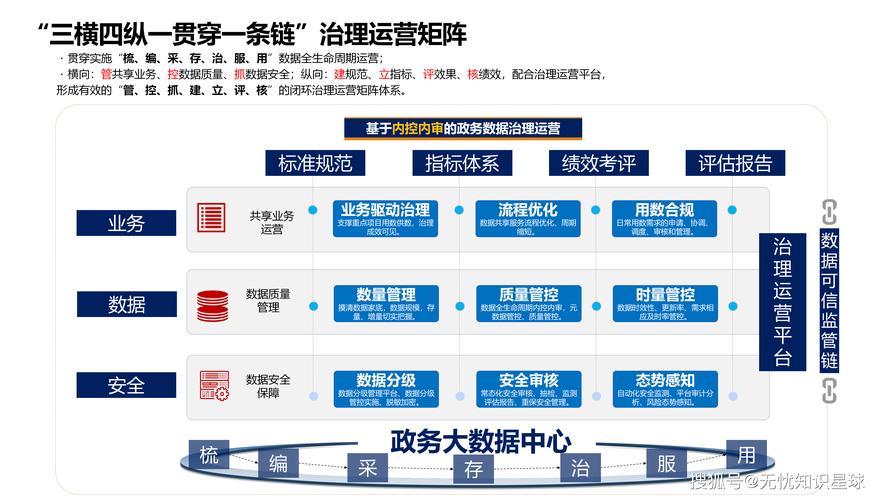
未来的关键在于构建一个负责任的政府数据生态系统:
- 顶层设计: 出台国家层面的数据治理法律,明确数据权属、使用边界和责任追究。
- 技术保障: 推广隐私计算、联邦学习等技术,实现“数据可用不可见”,在保护隐私的前提下发挥数据价值。
- 制度制衡: 建立独立的数据伦理审查委员会和监督机构,对政府的数据决策进行评估和监督。
- 公众参与: 鼓励公众讨论数据治理的规则,提升全民数字素养,让数据发展成果真正惠及每一个人。
目标是让技术成为服务于人的工具,而不是控制人的枷锁,实现科技向善,善治为民。


