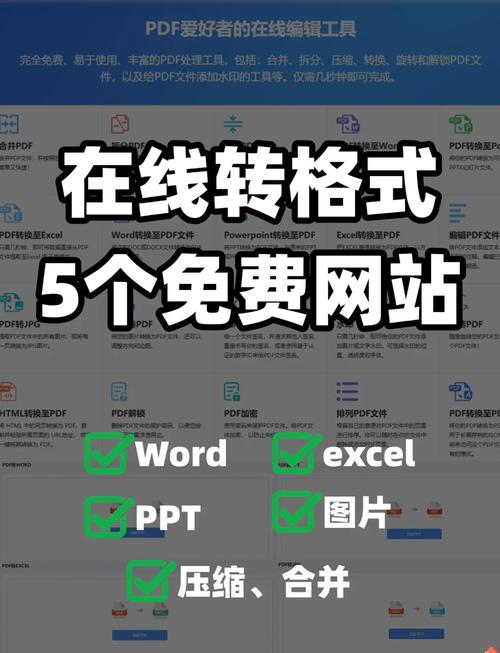
核心原理:为什么不能直接用 <img>
PDF 是一种复杂的文档格式,它包含矢量图形、文本层、字体、加密信息等,普通的图片标签 <img> 无法解析这些复杂结构,直接显示 PDF 文件通常会导致浏览器下载它,而不是在页面上预览。
 (图片来源网络,侵删)
(图片来源网络,侵删)
我们需要借助“翻译器”——JavaScript PDF 渲染库,将 PDF 的内容“翻译”成浏览器可以理解的格式(通常是 HTML5 Canvas 或 SVG),然后渲染到网页上。
主流实现方案对比
目前主要有三种主流的在线 PDF 浏览方案,各有优劣,适用于不同的场景。
方案
核心技术
优点
缺点
适用场景
客户端渲染
PDF.js
- 纯前端,无需服务器处理,减轻服务器负担
- 开源免费,社区活跃
- 功能强大,可高度定制
- 首次加载时需要下载 PDF.js 库,可能影响首屏速度
- 大文件或多页渲染可能占用较多客户端内存和CPU
- 静态文档展示(如产品手册、电子书)
- 对加载速度要求不高的场景
- 需要离线访问或数据隐私要求高的场景
服务端渲染
PDF to Image
- 首屏加载极快,用户体验好
- 服务器端处理,客户端负担小
- 服务器开销大,CPU 和内存消耗高
- 服务器需要安装额外库(如 pdf2pic, pdf2image)
- 无法进行文本选择、复制等交互
- 需要快速加载的文档门户
- 对客户端性能要求低的场景
- PDF 文件不经常变动
第三方服务
Google Docs Viewer, PDF.js Viewer
- 集成最简单,几行代码即可实现
- 免费,有大型公司技术支持(如 Google)
- 依赖外部服务,有可用性风险
- 存在隐私和安全问题,文件会上传到第三方服务器
- 自定义程度低,有广告或品牌限制
- 快速原型验证
- 内部工具,对隐私要求不高的场景
- 不想自己维护代码的情况
客户端渲染 (推荐,最常用)
我们以 Mozilla 开源的 PDF.js 为例,这是目前最流行、功能最强大的前端 PDF 渲染库。
实现步骤:
准备工作
 (图片来源网络,侵删)
(图片来源网络,侵删)
- 一个 HTML 文件 (e.g.,
index.html)
- 一个 PDF 文件 (e.g.,
sample.pdf),放在与 index.html 同一个目录下,或者一个可公开访问的 URL。
引入 PDF.js 库
最简单的方式是通过 CDN 引入,在 <head> 标签中添加:
<!-- 引入 PDF.js 的核心库 -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/3.11.174/pdf.min.js"></script>
<!-- 设置 worker 脚本的路径,PDF.js 使用 Web Worker 来在后台处理 PDF,避免阻塞主线程 -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/3.11.174/pdf.worker.min.js"></script>
创建 HTML 结构
在 <body> 中,我们需要一个容器来放置渲染出的 PDF 页面,以及一个 <canvas> 元素来绘制每一页。
 (图片来源网络,侵删)
(图片来源网络,侵删)
<div class="pdf-container">
<div id="pdf-viewer"></div>
</div>
编写 JavaScript 代码
这是最关键的一步,我们将编写脚本来加载 PDF 文件,逐页渲染到 canvas 上。
<script>
// PDF.js 的全局 worker 路径配置
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://cdnjs.cloudflare.com/ajax/libs/pdf.js/3.11.174/pdf.worker.min.js';
// PDF 文件的路径
const pdfUrl = 'sample.pdf'; // 或者使用网络 URL,如 'https://example.com/files/document.pdf'
// 获取渲染容器
const pdfViewer = document.getElementById('pdf-viewer');
// 异步函数,用于加载和渲染 PDF
async function loadPDF() {
try {
// 1. 获取 PDF 文件的数据
const pdf = await pdfjsLib.getDocument(pdfUrl).promise;
// 2. 获取 PDF 的总页数
const numPages = pdf.numPages;
console.log(`PDF 总页数: ${numPages}`);
// 3. 循环渲染每一页
for (let pageNum = 1; pageNum <= numPages; pageNum++) {
// 获取指定页
const page = await pdf.getPage(pageNum);
// 设置缩放比例,1.0 表示 100%
const scale = 1.5;
const viewport = page.getViewport({ scale: scale });
// 为每一页创建一个 canvas 元素
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
// 设置 canvas 的尺寸
canvas.height = viewport.height;
canvas.width = viewport.width;
// 将 canvas 添加到容器中
pdfViewer.appendChild(canvas);
// 渲染 PDF 页面到 canvas 上
const renderContext = {
canvasContext: context,
viewport: viewport
};
await page.render(renderContext).promise;
}
} catch (error) {
console.error('加载或渲染 PDF 时出错:', error);
pdfViewer.innerHTML = '<p>无法加载 PDF 文件,请检查文件路径或网络连接。</p>';
}
}
// 调用函数,开始加载
loadPDF();
</script>
添加基本样式 (可选)
为了让 PDF 页面垂直排列,可以添加一些 CSS:
<style>
body {
font-family: sans-serif;
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
margin: 0;
padding: 20px;
}
.pdf-container {
border: 1px solid #ccc;
box-shadow: 0 4px 8px rgba(0,0,0,0.1);
padding: 20px;
max-width: 100%;
overflow: auto; /* PDF 很宽,允许滚动 */
}
canvas {
display: block; /* 去除 canvas 底部的小间隙 */
margin-bottom: 20px; /* 页与页之间的间距 */
border: 1px solid #eee;
}
</style>
将以上所有代码整合到一个 index.html 文件中,用浏览器打开,你就能看到 PDF 的内容了。
服务端渲染 (以 Node.js 为例)
这种方案需要你的后端环境支持 Node.js。
安装依赖
在你的 Node.js 项目中安装 pdf2pic 库:
npm install pdf2pic
编写服务端代码 (e.g., server.js)
const express = require('express');
const pdf2pic = require('pdf2pic').fromPath;
const path = require('path');
const fs = require('fs');
const app = express();
const port = 3000;
// 静态文件服务,用于存放生成的图片和原始PDF
app.use(express.static('public'));
// 存放原始PDF的目录
const pdfDir = path.join(__dirname, 'pdfs');
// 存放生成图片的目录
const outputDir = path.join(__dirname, 'public', 'images');
// 确保目录存在
if (!fs.existsSync(pdfDir)) fs.mkdirSync(pdfDir);
if (!fs.existsSync(outputDir)) fs.mkdirSync(outputDir);
// 转换单个PDF页面的路由
app.get('/convert', async (req, res) => {
const { pdfName, page, options = { width: 800, height: 1000 } } = req.query;
if (!pdfName || !page) {
return res.status(400).send('PDF name and page number are required.');
}
const pdfPath = path.join(pdfDir, pdfName);
if (!fs.existsSync(pdfPath)) {
return res.status(404).send('PDF not found.');
}
const converter = pdf2pic(pdfPath, options);
try {
const result = await converter(page, 'image');
// result.path 是生成图片的绝对路径
// 我们需要返回相对于 public 目录的 URL
const imageUrl = path.join('images', path.basename(result.path));
res.json({ imageUrl: imageUrl });
} catch (error) {
console.error('Conversion error:', error);
res.status(500).send('Error converting PDF page.');
}
});
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}`);
});
创建前端页面 (e.g., public/index.html)
前端通过 AJAX 请求来获取每一页的图片 URL 并显示。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">Server-Side PDF Viewer</title>
<style>
body { font-family: sans-serif; text-align: center; }
#pdf-viewer { display: flex; flex-direction: column; align-items: center; }
#pdf-viewer img { max-width: 100%; border: 1px solid #ccc; margin-bottom: 10px; }
</style>
</head>
<body>
<h1>Server-Side PDF Viewer</h1>
<div id="pdf-viewer"></div>
<script>
// 假设我们想查看 'sample.pdf' 的前 5 页
const pdfName = 'sample.pdf';
const totalPages = 5;
const viewer = document.getElementById('pdf-viewer');
async function loadPDFPages() {
for (let i = 1; i <= totalPages; i++) {
try {
const response = await fetch(`/convert?pdfName=${pdfName}&page=${i}`);
const data = await response.json();
if (data.imageUrl) {
const img = document.createElement('img');
img.src = data.imageUrl;
viewer.appendChild(img);
}
} catch (error) {
console.error(`Failed to load page ${i}:`, error);
viewer.innerHTML += `<p>Failed to load page ${i}.</p>`;
}
}
}
loadPDFPages();
</script>
</body>
</html>
重要注意事项
-
文件路径:
- PDF 文件在服务器上,确保 Web 服务器有正确的读取权限。
- PDF 文件在 CDN 或其他域,需要确保该域允许跨域访问(CORS),否则 PDF.js 会因为安全策略而无法加载。
-
大文件性能:
- 对于几百页或非常大的 PDF 文件,一次性全部渲染会导致页面卡顿和内存溢出。
- 解决方案:实现分页加载或懒加载,只渲染当前可视区域内的页面,当用户滚动时再加载后续页面。
-
用户体验:
- 在 PDF 加载完成前,最好显示一个加载动画(如一个旋转的图标),告知用户“正在加载,请稍候...”。
- 考虑添加一个简单的工具栏,包含上一页、下一页、缩放等功能。
-
安全性:
PDF 包含敏感信息,请仔细评估使用第三方服务的风险,客户端渲染(PDF.js)通常是更安全的选择,因为文件不会离开用户的浏览器(除非你上传到自己的服务器)。
- 新手或快速实现:直接使用 PDF.js CDN 方案,代码简单,功能强大,是绝大多数场景下的首选。
- 追求极致首屏速度:如果你的应用对加载速度有苛刻要求,且服务器资源充足,可以考虑服务端渲染方案。
- 不想自己折腾:可以使用 Google Docs Viewer,但需接受其隐私和定制性限制。
希望这份详细的指南能帮助你成功实现网站上的在线 PDF 浏览功能!
PDF 是一种复杂的文档格式,它包含矢量图形、文本层、字体、加密信息等,普通的图片标签 <img> 无法解析这些复杂结构,直接显示 PDF 文件通常会导致浏览器下载它,而不是在页面上预览。
我们需要借助“翻译器”——JavaScript PDF 渲染库,将 PDF 的内容“翻译”成浏览器可以理解的格式(通常是 HTML5 Canvas 或 SVG),然后渲染到网页上。
主流实现方案对比
目前主要有三种主流的在线 PDF 浏览方案,各有优劣,适用于不同的场景。
| 方案 | 核心技术 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 客户端渲染 | PDF.js | - 纯前端,无需服务器处理,减轻服务器负担 - 开源免费,社区活跃 - 功能强大,可高度定制 |
- 首次加载时需要下载 PDF.js 库,可能影响首屏速度 - 大文件或多页渲染可能占用较多客户端内存和CPU |
- 静态文档展示(如产品手册、电子书) - 对加载速度要求不高的场景 - 需要离线访问或数据隐私要求高的场景 |
| 服务端渲染 | PDF to Image | - 首屏加载极快,用户体验好 - 服务器端处理,客户端负担小 |
- 服务器开销大,CPU 和内存消耗高 - 服务器需要安装额外库(如 pdf2pic, pdf2image)- 无法进行文本选择、复制等交互 |
- 需要快速加载的文档门户 - 对客户端性能要求低的场景 - PDF 文件不经常变动 |
| 第三方服务 | Google Docs Viewer, PDF.js Viewer | - 集成最简单,几行代码即可实现 - 免费,有大型公司技术支持(如 Google) |
- 依赖外部服务,有可用性风险 - 存在隐私和安全问题,文件会上传到第三方服务器 - 自定义程度低,有广告或品牌限制 |
- 快速原型验证 - 内部工具,对隐私要求不高的场景 - 不想自己维护代码的情况 |
客户端渲染 (推荐,最常用)
我们以 Mozilla 开源的 PDF.js 为例,这是目前最流行、功能最强大的前端 PDF 渲染库。
实现步骤:
准备工作
- 一个 HTML 文件 (e.g.,
index.html) - 一个 PDF 文件 (e.g.,
sample.pdf),放在与index.html同一个目录下,或者一个可公开访问的 URL。
引入 PDF.js 库
最简单的方式是通过 CDN 引入,在 <head> 标签中添加:
<!-- 引入 PDF.js 的核心库 --> <script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/3.11.174/pdf.min.js"></script> <!-- 设置 worker 脚本的路径,PDF.js 使用 Web Worker 来在后台处理 PDF,避免阻塞主线程 --> <script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/3.11.174/pdf.worker.min.js"></script>
创建 HTML 结构
在 <body> 中,我们需要一个容器来放置渲染出的 PDF 页面,以及一个 <canvas> 元素来绘制每一页。
<div class="pdf-container"> <div id="pdf-viewer"></div> </div>
编写 JavaScript 代码
这是最关键的一步,我们将编写脚本来加载 PDF 文件,逐页渲染到 canvas 上。
<script>
// PDF.js 的全局 worker 路径配置
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://cdnjs.cloudflare.com/ajax/libs/pdf.js/3.11.174/pdf.worker.min.js';
// PDF 文件的路径
const pdfUrl = 'sample.pdf'; // 或者使用网络 URL,如 'https://example.com/files/document.pdf'
// 获取渲染容器
const pdfViewer = document.getElementById('pdf-viewer');
// 异步函数,用于加载和渲染 PDF
async function loadPDF() {
try {
// 1. 获取 PDF 文件的数据
const pdf = await pdfjsLib.getDocument(pdfUrl).promise;
// 2. 获取 PDF 的总页数
const numPages = pdf.numPages;
console.log(`PDF 总页数: ${numPages}`);
// 3. 循环渲染每一页
for (let pageNum = 1; pageNum <= numPages; pageNum++) {
// 获取指定页
const page = await pdf.getPage(pageNum);
// 设置缩放比例,1.0 表示 100%
const scale = 1.5;
const viewport = page.getViewport({ scale: scale });
// 为每一页创建一个 canvas 元素
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
// 设置 canvas 的尺寸
canvas.height = viewport.height;
canvas.width = viewport.width;
// 将 canvas 添加到容器中
pdfViewer.appendChild(canvas);
// 渲染 PDF 页面到 canvas 上
const renderContext = {
canvasContext: context,
viewport: viewport
};
await page.render(renderContext).promise;
}
} catch (error) {
console.error('加载或渲染 PDF 时出错:', error);
pdfViewer.innerHTML = '<p>无法加载 PDF 文件,请检查文件路径或网络连接。</p>';
}
}
// 调用函数,开始加载
loadPDF();
</script>
添加基本样式 (可选)
为了让 PDF 页面垂直排列,可以添加一些 CSS:
<style>
body {
font-family: sans-serif;
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
margin: 0;
padding: 20px;
}
.pdf-container {
border: 1px solid #ccc;
box-shadow: 0 4px 8px rgba(0,0,0,0.1);
padding: 20px;
max-width: 100%;
overflow: auto; /* PDF 很宽,允许滚动 */
}
canvas {
display: block; /* 去除 canvas 底部的小间隙 */
margin-bottom: 20px; /* 页与页之间的间距 */
border: 1px solid #eee;
}
</style>
将以上所有代码整合到一个 index.html 文件中,用浏览器打开,你就能看到 PDF 的内容了。
服务端渲染 (以 Node.js 为例)
这种方案需要你的后端环境支持 Node.js。
安装依赖
在你的 Node.js 项目中安装 pdf2pic 库:
npm install pdf2pic
编写服务端代码 (e.g., server.js)
const express = require('express');
const pdf2pic = require('pdf2pic').fromPath;
const path = require('path');
const fs = require('fs');
const app = express();
const port = 3000;
// 静态文件服务,用于存放生成的图片和原始PDF
app.use(express.static('public'));
// 存放原始PDF的目录
const pdfDir = path.join(__dirname, 'pdfs');
// 存放生成图片的目录
const outputDir = path.join(__dirname, 'public', 'images');
// 确保目录存在
if (!fs.existsSync(pdfDir)) fs.mkdirSync(pdfDir);
if (!fs.existsSync(outputDir)) fs.mkdirSync(outputDir);
// 转换单个PDF页面的路由
app.get('/convert', async (req, res) => {
const { pdfName, page, options = { width: 800, height: 1000 } } = req.query;
if (!pdfName || !page) {
return res.status(400).send('PDF name and page number are required.');
}
const pdfPath = path.join(pdfDir, pdfName);
if (!fs.existsSync(pdfPath)) {
return res.status(404).send('PDF not found.');
}
const converter = pdf2pic(pdfPath, options);
try {
const result = await converter(page, 'image');
// result.path 是生成图片的绝对路径
// 我们需要返回相对于 public 目录的 URL
const imageUrl = path.join('images', path.basename(result.path));
res.json({ imageUrl: imageUrl });
} catch (error) {
console.error('Conversion error:', error);
res.status(500).send('Error converting PDF page.');
}
});
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}`);
});
创建前端页面 (e.g., public/index.html)
前端通过 AJAX 请求来获取每一页的图片 URL 并显示。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">Server-Side PDF Viewer</title>
<style>
body { font-family: sans-serif; text-align: center; }
#pdf-viewer { display: flex; flex-direction: column; align-items: center; }
#pdf-viewer img { max-width: 100%; border: 1px solid #ccc; margin-bottom: 10px; }
</style>
</head>
<body>
<h1>Server-Side PDF Viewer</h1>
<div id="pdf-viewer"></div>
<script>
// 假设我们想查看 'sample.pdf' 的前 5 页
const pdfName = 'sample.pdf';
const totalPages = 5;
const viewer = document.getElementById('pdf-viewer');
async function loadPDFPages() {
for (let i = 1; i <= totalPages; i++) {
try {
const response = await fetch(`/convert?pdfName=${pdfName}&page=${i}`);
const data = await response.json();
if (data.imageUrl) {
const img = document.createElement('img');
img.src = data.imageUrl;
viewer.appendChild(img);
}
} catch (error) {
console.error(`Failed to load page ${i}:`, error);
viewer.innerHTML += `<p>Failed to load page ${i}.</p>`;
}
}
}
loadPDFPages();
</script>
</body>
</html>
重要注意事项
-
文件路径:
- PDF 文件在服务器上,确保 Web 服务器有正确的读取权限。
- PDF 文件在 CDN 或其他域,需要确保该域允许跨域访问(CORS),否则 PDF.js 会因为安全策略而无法加载。
-
大文件性能:
- 对于几百页或非常大的 PDF 文件,一次性全部渲染会导致页面卡顿和内存溢出。
- 解决方案:实现分页加载或懒加载,只渲染当前可视区域内的页面,当用户滚动时再加载后续页面。
-
用户体验:
- 在 PDF 加载完成前,最好显示一个加载动画(如一个旋转的图标),告知用户“正在加载,请稍候...”。
- 考虑添加一个简单的工具栏,包含上一页、下一页、缩放等功能。
-
安全性:
PDF 包含敏感信息,请仔细评估使用第三方服务的风险,客户端渲染(PDF.js)通常是更安全的选择,因为文件不会离开用户的浏览器(除非你上传到自己的服务器)。
- 新手或快速实现:直接使用 PDF.js CDN 方案,代码简单,功能强大,是绝大多数场景下的首选。
- 追求极致首屏速度:如果你的应用对加载速度有苛刻要求,且服务器资源充足,可以考虑服务端渲染方案。
- 不想自己折腾:可以使用 Google Docs Viewer,但需接受其隐私和定制性限制。
希望这份详细的指南能帮助你成功实现网站上的在线 PDF 浏览功能!


