重要声明:法律与道德警告
在开始之前,你必须了解以下几点:

(图片来源网络,侵删)
-
合法性:抓取数据本身并不违法,但用途和方式至关重要。
- 查看
robots.txt:几乎所有网站都有一个robots.txt文件(https://www.example.com/robots.txt),它规定了哪些页面允许或禁止爬虫访问,遵守robots.txt是行业惯例,虽然不具法律强制力,但无视它可能被视为恶意行为。 - 服务条款:许多网站的服务条款中明确禁止自动化访问,违反条款可能导致你的 IP 被封禁,甚至面临法律诉讼。
- 版权与数据所有权:网站的内容和数据通常受版权保护,你抓取的数据不能用于商业用途,除非获得明确授权。
- GDPR 等隐私法规:如果你抓取的数据包含个人身份信息,你必须严格遵守相关数据保护法规(如欧盟的 GDPR)。
- 查看
-
道德性:
- 不要对服务器造成过大负担:频繁、高速的请求会消耗对方服务器的资源和带宽,影响网站正常用户的使用,这是非常不道德的行为,甚至可能构成违法行为。
- 注明数据来源:如果你使用抓取的数据进行二次创作或展示,最好注明原始来源。
核心原则: 只抓取公开、非个人、且不会对目标网站造成负担的数据,并始终遵守其规则。
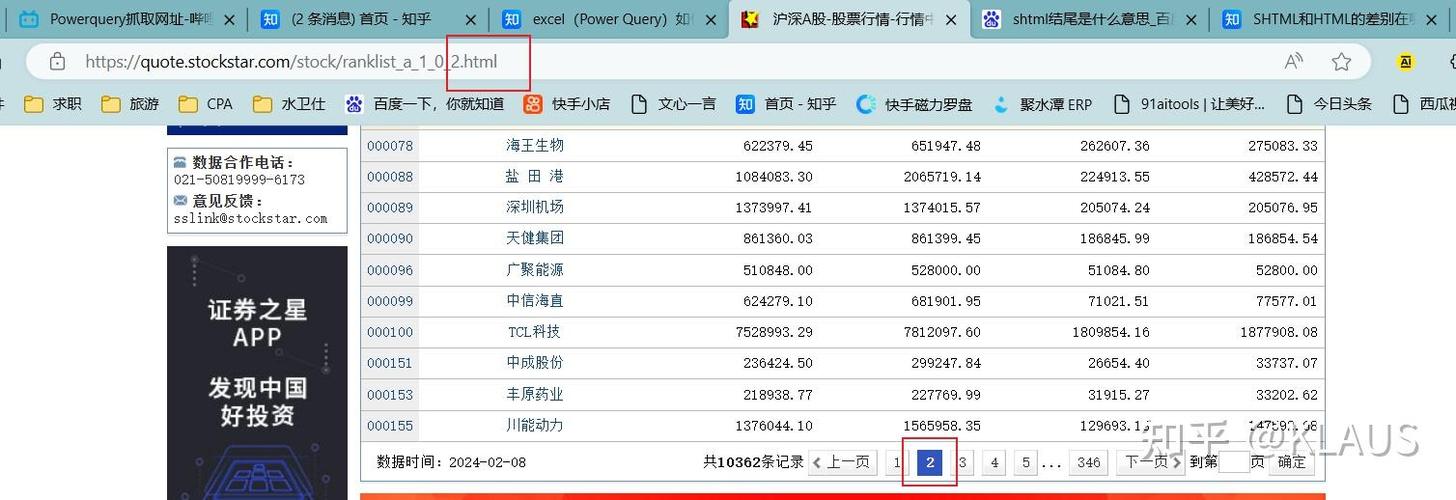
第一步:明确你的目标
在动手之前,先问自己几个问题:
(图片来源网络,侵删)
- 要抓什么? 是文章标题、价格、图片链接,还是整个页面的结构?
- 抓多少? 是抓取所有历史数据,还是每天只更新最新数据?
- 怎么用? 是用于个人学习、研究,还是商业产品?这决定了你的抓取策略和频率。
第二步:选择合适的工具和技术
根据你的技术水平和项目复杂度,可以选择不同的工具。
新手入门:使用可视化工具
这类工具无需编写代码,通过图形界面配置任务即可。
- Octoparse / ParseHub:非常流行的可视化爬虫工具,你只需在浏览器中点击页面元素,它就能帮你识别并抓取数据,适合抓取结构化数据(如列表、表格)。
- Web Scraper 浏览器插件:如果你只需要抓取一个或几个简单网页,可以安装浏览器插件(如 Chrome 的 "Web Scraper"),它可以在当前页面上直接定义抓取规则。
优点:门槛低,快速上手。 缺点:灵活性差,处理复杂逻辑(如登录、分页)困难,稳定性不高。
进阶玩家:编写脚本(Python 是首选)
对于大多数需要定制化的抓取任务,使用编程语言是最佳选择。Python 是公认的最佳选择,因为它拥有强大的爬虫库生态系统。
(图片来源网络,侵删)
Python 爬虫三剑客:
- Requests:用于发送 HTTP 请求,获取网页的 HTML 内容,这是最基础的一步。
- Beautiful Soup:用于解析 HTML 和 XML 文档,它能帮你轻松地从杂乱的 HTML 中提取出你需要的数据。
- Selenium:用于模拟浏览器行为,当网站使用大量 JavaScript 动态加载数据时,
Requests无法获取最终渲染的页面,这时就需要Selenium来驱动一个真实的浏览器(如 Chrome)进行抓取。
其他工具:
- Scrapy:一个功能强大的爬虫框架,当你需要构建大规模、可维护的爬虫项目时,Scrapy 是不二之选,它包含了请求调度、数据提取、管道处理等全套功能。
- Playwright / Puppeteer:新一代的浏览器自动化工具,比 Selenium 更快、更稳定,支持多种浏览器(Chromium, Firefox, WebKit)。
第三步:实战演练(Python 示例)
我们以抓取某个博客的文章标题和链接为例,展示一个简单的流程。
静态页面(纯 HTML)
假设目标网站的文章列表是直接写在 HTML 里的。
步骤:
-
安装库:
pip install requests beautifulsoup4
-
编写脚本 (
simple_scraper.py):import requests from bs4 import BeautifulSoup import time # 目标 URL url = 'https://example-blog.com/posts' # 替换成你想要抓取的网站 # 1. 发送 HTTP 请求 try: # 添加 User-Agent 模拟浏览器访问,避免被识别为爬虫 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } response = requests.get(url, headers=headers, timeout=10) # 检查请求是否成功 response.raise_for_status() except requests.exceptions.RequestException as e: print(f"请求失败: {e}") exit() # 2. 解析 HTML soup = BeautifulSoup(response.text, 'html.parser') # 3. 提取数据 (需要你用浏览器开发者工具分析页面结构) # 假设文章标题都在 <h2 class="post-title"> 标签里,链接在 <a> 标签里 post_titles = soup.find_all('h2', class_='post-title') print("--- 抓取到的文章标题和链接 ---") for title in post_titles: # 标题文本 title_text = title.get_text(strip=True) # 链接 (假设 <h2> 内部的 <a> 标签) link = title.find('a')['href'] if link.startswith('/'): # 处理相对路径 link = 'https://example-blog.com' + link print(f"标题: {title_text}") print(f"链接: {link}") print("-" * 20) # 4. 礼貌性等待 time.sleep(2) # 等待2秒,避免请求过快
动态页面(JavaScript 渲染)
如果数据是通过 JavaScript 动态加载的,上面的方法会抓取到空数据,这时需要 Selenium。
步骤:
-
安装库和浏览器驱动:
pip install selenium
- 下载对应你 Chrome 版本的 ChromeDriver,并将其路径添加到系统环境变量,或直接在代码中指定路径。
-
编写脚本 (
dynamic_scraper.py):from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time # ChromeDriver 的路径 (如果你没有把它放到环境变量里) # service = Service(executable_path='/path/to/your/chromedriver') # driver = webdriver.Chrome(service=service) # 如果环境变量配置好了,可以直接这样启动 driver = webdriver.Chrome() url = 'https://example-dynamic-site.com' # 替换成动态网站 driver.get(url) try: # 等待最多10秒,直到某个元素出现(证明数据已加载) # 这里我们假设数据加载后会有一个 id 为 'post-list' 的容器 WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, 'post-list')) ) # 数据加载完成后,获取页面源代码 page_source = driver.page_source # 接下来可以用 BeautifulSoup 来解析这个已经渲染好的 HTML from bs4 import BeautifulSoup soup = BeautifulSoup(page_source, 'html.parser') # 提取数据的逻辑和之前一样... # ... finally: # 无论成功与否,最后都要关闭浏览器 driver.quit()
第四步:应对反爬机制
网站为了防止被爬取,会设置各种障碍,你需要学会应对:
-
IP 被封:
- 解决方法:使用代理 IP,你可以购买付费代理服务,或者使用免费的代理(但稳定性差),Scrapy 框架内置了代理支持。
-
验证码:
- 解决方法:
- 简单图形验证码:可以使用 Tesseract-OCR 等库进行识别。
- 复杂验证码(如 reCAPTCHA):手动识别或使用第三方打码平台(如 2Captcha, Anti-Captcha),但这会增加成本。
- 解决方法:
-
登录状态:
- 解决方法:使用
requests.Session()或selenium来保持登录的cookies,这样后续请求就能保持登录状态。
- 解决方法:使用
-
请求频率限制:
- 解决方法:在代码中加入
time.sleep(random.uniform(1, 3)),让每次请求之间有一个随机的间隔,模拟人类行为。
- 解决方法:在代码中加入
总结与最佳实践
- 从简单开始:先尝试抓取静态页面,再挑战动态页面。
- 分析页面结构:善用浏览器的“开发者工具”(F12)来检查 HTML 元素,这是抓取的核心技能。
- 遵守规则:始终检查
robots.txt,控制请求频率,不要给对方服务器造成压力。 - 优雅地处理错误:网络请求可能会失败,代码需要有
try-except来处理异常。 - 数据存储:抓取到的数据可以保存为 CSV、JSON 文件,或者存入数据库(如 SQLite, MySQL)。
- 持续学习:爬虫技术发展很快,关注新的库和框架(如 Playwright),学习更高级的技巧(如分布式爬虫 Scrapy-Redis)。
希望这份指南能帮助你安全、合法地开始你的数据抓取之旅!


