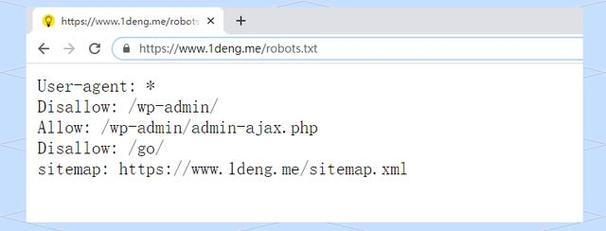
什么是 robots.txt?
robots.txt(也称为“爬虫协议”或“机器人排除协议”)是一个纯文本文件,网站所有者通过它来告知搜索引擎的爬虫(如Googlebot、Bingbot等)哪些页面或部分可以抓取,哪些不可以。
(图片来源网络,侵删)
重要前提:
- 这是一个“请求”,而非“命令”,遵守
robots.txt是爬虫的礼貌行为,但并非所有爬虫都会遵守,恶意爬虫或不良行为者完全可以忽略这个文件。 - 它不阻止页面被索引,如果一个页面被
robots.txt禁止抓取,它仍然可能出现在搜索结果中,如果其他网站链接到这个页面,搜索引擎可能会通过那个链接发现它并将其索引,要彻底阻止页面被索引,需要使用noindex标签(在 HTML 的<head>部分添加<meta name="robots" content="noindex">)。
robots.txt 文件的作用
- 控制服务器负载:防止搜索引擎爬虫抓取那些对用户没有价值但会消耗大量服务器资源的页面(如搜索结果页、后台管理页面)。
- 保护隐私和敏感数据:阻止搜索引擎抓取包含用户个人信息、内部数据或私人内容的页面。
- 优化抓取预算:对于大型网站,搜索引擎的抓取资源(抓取预算)是有限的,通过
robots.txt指导爬虫优先抓取最重要的页面,确保关键内容能被及时索引。 - 避免重复内容问题:可以禁止抓取打印版本、排序不同的列表页等,防止搜索引擎因内容相似而产生困惑。
robots.txt 文件的基本语法和结构
robots.txt 文件非常简单,由几条基本规则组成。
User-agent (用户代理)
这是规则适用的对象,它指定了哪款爬虫应该遵守这些规则。
- 通配符,代表所有爬虫,这是最常见的用法。
Googlebot:仅针对 Google 的爬虫。Bingbot:仅针对 Bing 的爬虫。Mediapartners-Google:针对 Google AdSense 的爬虫(它只抓取内容以投放相关广告,不关心索引)。
注意: User-agent 是区分大小写的。

(图片来源网络,侵删)
Disallow (禁止)
指定一个或多个不允许抓取的 URL 路径。
- 禁止抓取整个网站。
/private/:禁止抓取private目录下的所有页面。/admin.php:禁止抓取特定的admin.php文件。- 井号后面的内容是注释,会被忽略。
Allow (允许)
与 Disallow 相对,指定一个或多个允许抓取的 URL 路径,这通常用于在一个 broader 的禁止规则下开放特定区域。
/private/public/:/private/被禁止,但/private/public/需要被允许,就可以使用Allow。
Sitemap (网站地图)
这是一个非常重要的指令,它告诉搜索引擎你网站 sitemap.xml 文件的位置,这有助于搜索引擎更高效地发现你网站的所有页面,尤其是那些通过链接可能难以发现的页面。
Sitemap: https://www.example.com/sitemap.xml
示例分析
让我们来看几个常见的 robots.txt 文件示例。
(图片来源网络,侵删)
示例 1:最简单的配置
适用于大多数小型网站。
User-agent: * Disallow:
- 解读:对所有爬虫(
User-agent: *)说,没有任何禁止抓取的路径(Disallow:),这等同于没有这个文件,告诉爬虫可以抓取所有内容。
示例 2:禁止所有爬虫访问整个网站
一个正在开发中的网站,不希望被搜索引擎收录。
User-agent: * Disallow: /
- 解读:对所有爬虫,禁止抓取根目录下的所有内容(
Disallow: /),即整个网站。
示例 3:一个典型的电商网站配置
User-agent: * # 允许所有爬虫访问所有页面 Allow: / # 但禁止抓取特定目录和文件 Disallow: /admin/ Disallow: /cart/ Disallow: /checkout/ Disallow: /account/ Disallow: /tmp/ Disallow: /search.php # 指定网站地图位置 Sitemap: https://www.example.com/sitemap.xml
- 解读:这个配置允许抓取所有公开内容,但禁止爬虫访问管理后台、购物车、结账、用户账户和临时文件等敏感或对用户无直接价值的页面。
示例 4:针对特定爬虫的精细控制
# 对所有爬虫,禁止抓取两个特定目录 User-agent: * Disallow: /private/ Disallow: /junk/ # 但特别允许 Googlebot 抓取 /private/public/ 目录 User-agent: Googlebot Allow: /private/public/ # 指定网站地图 Sitemap: https://www.example.com/sitemap.xml
- 解读:这个配置有两个部分。
- 对所有爬虫,禁止抓取
/private/和/junk/。 - 专门针对
Googlebot,开放了/private/public/目录,即使它在全局规则中被禁止了。
- 对所有爬虫,禁止抓取
如何创建和放置 robots.txt 文件?
- 创建文件:使用任何文本编辑器(如记事本、VS Code、Sublime Text)创建一个名为
robots.txt的文件。 - 编写规则:按照上述语法编写你的规则。
- 上传文件:将
robots.txt文件上传到你的网站根目录下,这是最重要的!- 正确位置:
https://www.example.com/robots.txt - 错误位置:
https://www.example.com/folder/robots.txt(搜索引擎找不到它)
- 正确位置:
如何检查你的 robots.txt 文件?
你可以通过以下方式检查和测试你的 robots.txt 文件:
- 直接访问:在浏览器地址栏输入
https://www.yourdomain.com/robots.txt,直接查看文件内容。 - Google Search Console (谷歌站长工具):
- 登录你的 Google Search Console。
- 在左侧菜单中选择“抓取工具” > “robots.txt 测试器”。
- 在这里你可以输入任何 URL,测试特定爬虫是否可以抓取它,并能实时看到文件内容。
- Bing Webmaster Tools:提供了类似的“Robots.txt Tester”功能。
常见错误和最佳实践
常见错误
- 文件位置错误:没有放在根目录。
- 语法错误:拼写错误、大小写错误、缺少空格或换行。
- 过度使用
Disallow: /:不小心禁止了整个网站,导致所有页面都无法被索引。 - 以为
Disallow能阻止索引:混淆了抓取和索引的概念,要阻止索引,必须使用noindex
最佳实践
- 明确简洁:保持文件简单明了,只包含必要的规则。
- 优先使用
Allow:在一个大范围禁止的规则下,用Allow来开放特定区域,比写一堆Disallow更清晰。 - 始终包含
Sitemap:这是帮助搜索引擎发现你网站所有内容的最简单有效的方法。 - 定期检查:当你网站结构发生变化时(如改版、添加新目录),记得更新并检查你的
robots.txt文件。 - 不要用
robots.txt隐藏“黑帽”内容:因为Disallow只是一个请求,恶意行为者仍然可以找到这些页面,更重要的是,如果这些页面被其他网站链接,它们还是可能被索引,真正的敏感内容应该通过服务器认证(如登录)来保护。
robots.txt 是一个强大而简单的工具,是网站与搜索引擎沟通的第一道桥梁,正确配置它,可以帮助你更好地管理网站在搜索引擎中的表现,保护敏感数据,并优化爬虫的抓取效率,虽然它不是万能的,但合理使用绝对是网站管理中不可或缺的一环。


